Machine Learning Research at Georgia Tech
Glenn Matlin
Studying how language models learn about people.
I study artificial intelligence, machine learning, and language models, with a focus on social reasoning, evaluation, and interpretability in finance, wargaming, law, and other high-stakes domains.

Selected Work
Each project asks the same question from a different angle: what do models infer about people, and how do we test whether that understanding is real?
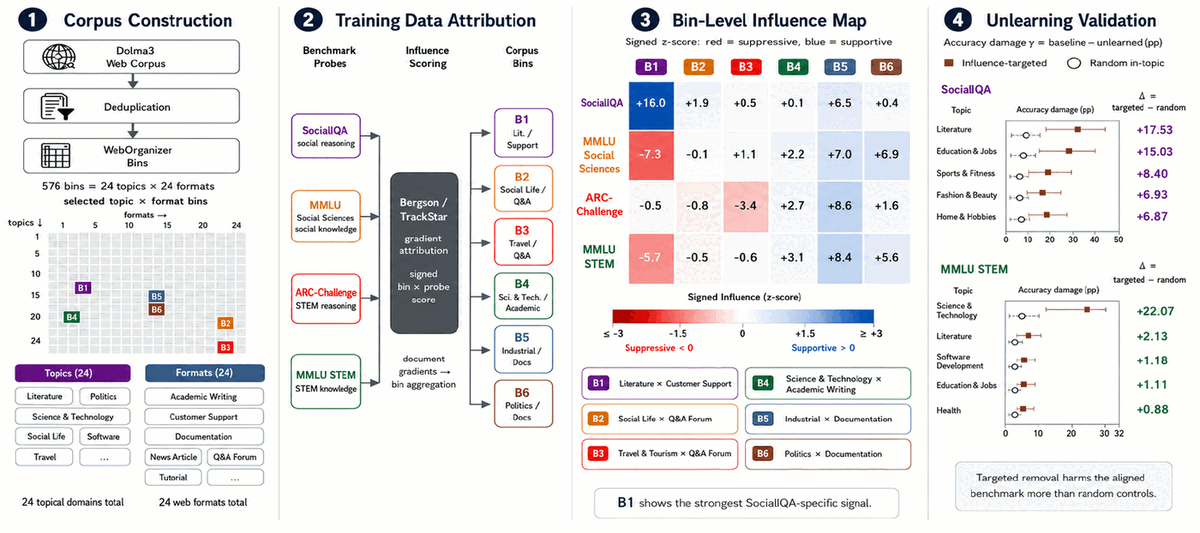
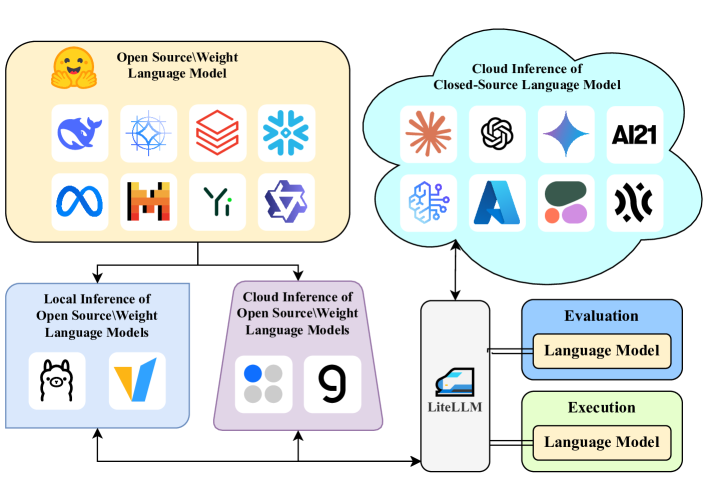
Financial Language Model Evaluation (FLaME)
Ran 23 foundation models across 20 core financial tasks to find where domain fluency is real and where it collapses under evaluation pressure.
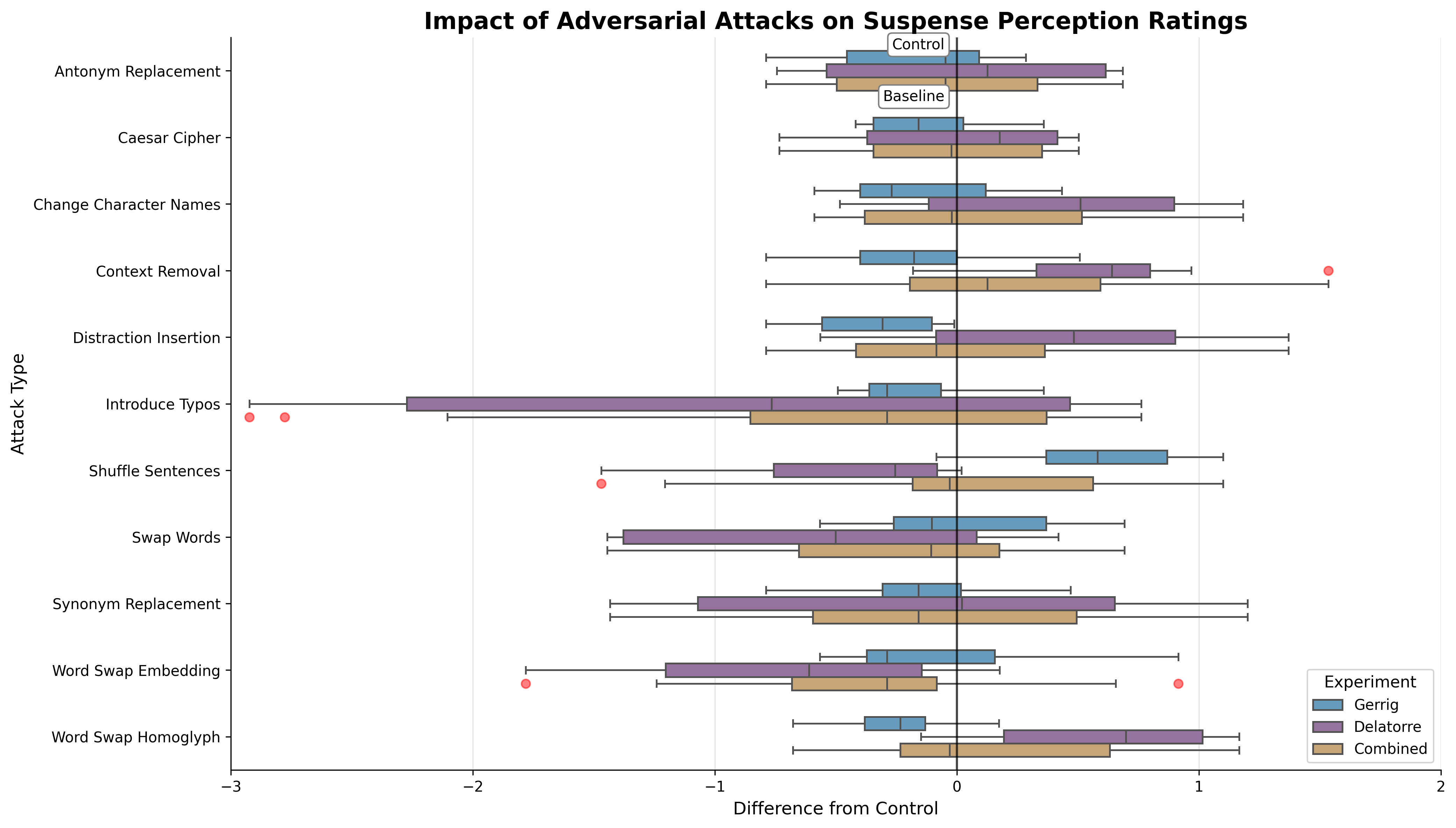
Do Language Models Agree with Human Perceptions of Suspense in Stories?
Tested whether models feel narrative tension where readers do, and found where their sense of suspense lines up with people and where it doesn’t.
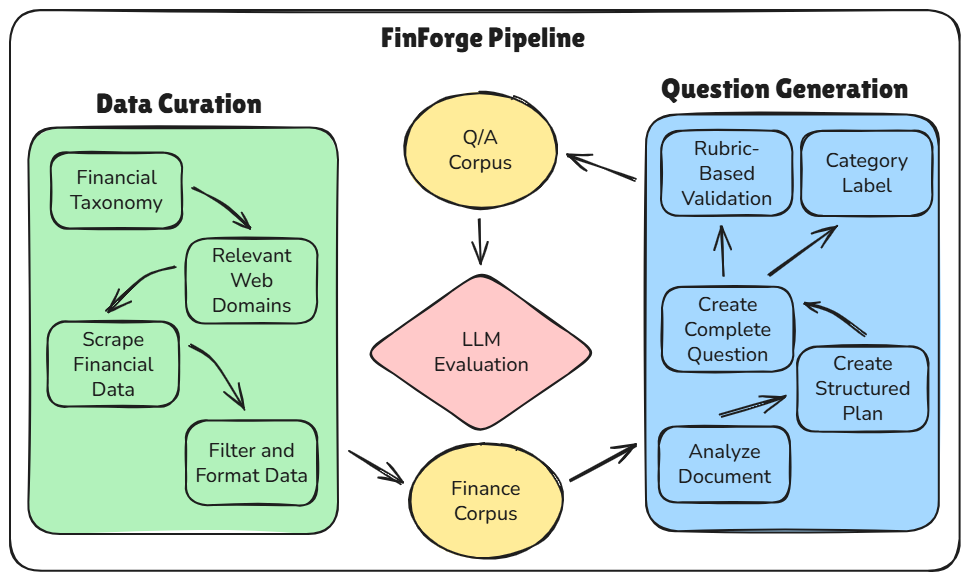
FinForge: Semi-Synthetic Financial Benchmark Generation
Generated financial evaluation data on demand so benchmarks stay usable when privacy, rarity, or cost make real datasets too thin.
News
-
Jul 2026
“Capability Provenance in Language Models” accepted to COLM 2026.
-
Jan 2026
FinForge presented at the AAAI 2026 Agentic AI in Financial Services workshop.
-
Dec 2025
FIFE presented at the NeurIPS 2025 GenAI Finance workshop, evaluating 53 models.
-
Aug 2025
Suspense study accepted to COLM 2025, in the top 3% of submissions.
-
Jun 2025
FLaME published in Findings of ACL 2025.
Where This Matters
I work where models interact with people, institutions, and incentives rather than clean toy tasks.
Finance
Language models meet regulation, incentives, and real decision costs here. That makes evaluation grounded rather than abstract.
Strategy & Wargaming
Open-ended planning exposes whether a model can track beliefs, goals, and uncertainty over time instead of pattern-matching one step at a time.
Institutions
Law, healthcare, and other institutional settings are where social misunderstanding turns into brittle automation, bad advice, or manipulation risk.
Collaborate
If you’re working on model behavior, interpretability, or high-stakes evaluation, I’d love to compare notes.